环境:CentOS Linux release 7.5.1804 (Core)、5.5.60-MariaDB
运行方式:Prometheus,Grafana和Alertmanager通过docker安装运行,MySQL和exporter直接运行在VM上
安装 1 2 3 4 5 6 7 8 docker pull prom/prometheus docker pull grafana/grafana docker pull prom/alertmanager [root@VM_0_2_centos config] REPOSITORY TAG IMAGE ID CREATED SIZE prom/prometheus latest f57ed0abd85c 2 days ago 109MB grafana/grafana latest ffd9c905f698 8 days ago 241MB prom/alertmanager latest 02e0d8e930da 6 weeks ago 42.5MB
执行prometheus前,先配置好以下文件。
1 2 3 4 5 6 7 8 9 [root@zabbix02 ~]# tree config/ config/ ├── alertmanager │ ├── alertmanager.yml │ └── template │ └── test.tmpl └── prometheus ├── prometheus.yml └── rules.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 global: scrape_interval: 15s evaluation_interval: 15s scrape_timeout: 15s external_labels: monitor: 'codelab_monitor' alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"] rule_files: - "rules.yml" scrape_configs: - job_name: 'node' scrape_interval: 5s static_configs: - targets: ['localhost:9100'] - job_name: 'prometheus' scrape_interval: 5s static_configs: - targets: ['localhost:9090'] - job_name: 'mysqld' scrape_interval: 5s static_configs: - targets: ['localhost:9104']
1 2 3 4 5 6 7 8 9 10 11 12 groups: - name: test-rules rules: - alert: hostCpuUsageAlert expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance) * 100 > 20 for: 1s labels: severity: page annotations: summary: "Instance {{ $labels.instance }} CPU usgae high" description: "{{ $labels.instance }} CPU usage above 20% (current value: {{ $value }} )"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 global: resolve_timeout: 5m smtp_smarthost: 'smtp.163.com:465' smtp_from: 'xxx@163.com' smtp_auth_username: 'xxx@163.com' smtp_auth_password: 'xxxxxxxx' wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' templates: - 'template/*.tmpl' route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1m receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://127.0.0.1:5001/' - name: 'email' email_configs: - to: 'xxx@yyy.com' html: '{{ template "test.html" . }} ' headers: { Subject: "[WARN] 报警邮件" } - name: 'qywx' webhook_configs: - send_resolved: true to_party: '1' agent_id: 'xxxxxx' corp_id: 'xxxxxx' api_secret: 'xxxxxx' message: '{{ template "test.html" . }} '
这里不使用docker方式运行exporter,通过下载安装包安装node_exporter和mysqld_exporter。
1 2 3 4 5 6 7 8 9 10 wget https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gz tar -xf node_exporter-0.17.0.linux-amd64.tar.gz cd node_exporter-0.17.0.linux-amd64/nohup ./node_exporter & [root@zabbix02 node_exporter-0.17.0.linux-amd64] tcp6 0 0 :::9100 :::* LISTEN 21164/./node_export tcp6 0 0 ::1:9100 ::1:57580 ESTABLISHED 21164/./node_export
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/mysqld_exporter-0.11.0.linux-amd64.tar.gz tar -xf mysqld_exporter-0.11.0.linux-amd64.tar.gz cd exporter/mysqld_exporter-0.11.0.linux-amd64/cat <<EOF >.my.cnf [client] user=exporter password=exporter EOF CREATE USER 'exporter' @'localhost' IDENTIFIED BY 'exporter' ; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter' @'localhost' ; nohup ./mysqld_exporter --config.my-cnf="./.my.cnf" &
1 2 3 docker run -d -p 9090:9090 --name prometheus --net=host \ -v /root/config/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \ -v /root/config/prometheus/rules.yml:/etc/prometheus/rules.yml prom/prometheus
1 2 3 docker run -d -p 9093:9093 --net=host \ -v /root/config/alertmanager/alertmanager.yml:/etc/alertmanager/config.yml \ --name alertmanager prom/alertmanager
要通过grafana展示监控数据,见https://github.com/zlzgithub/docs/blob/master/grafana/grafana-intro.md
以上步骤就绪后,通过浏览器访问看看
http://192.168.100.150:9090/graph
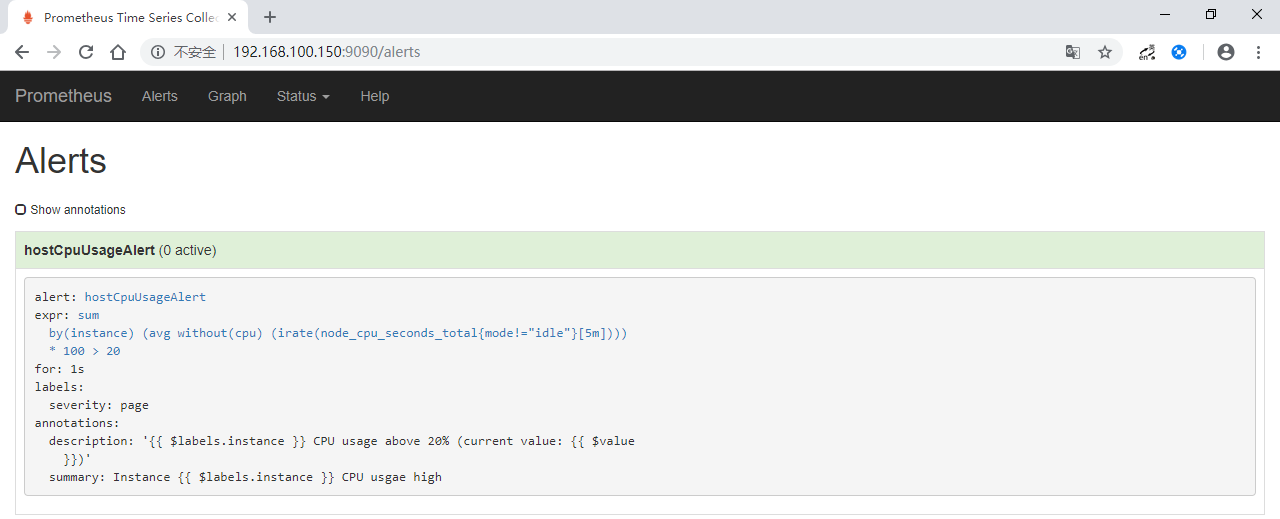
http://192.168.100.150:9090/alerts ,显示了一条报警规则,说明此前的prometheus rules配置正常。
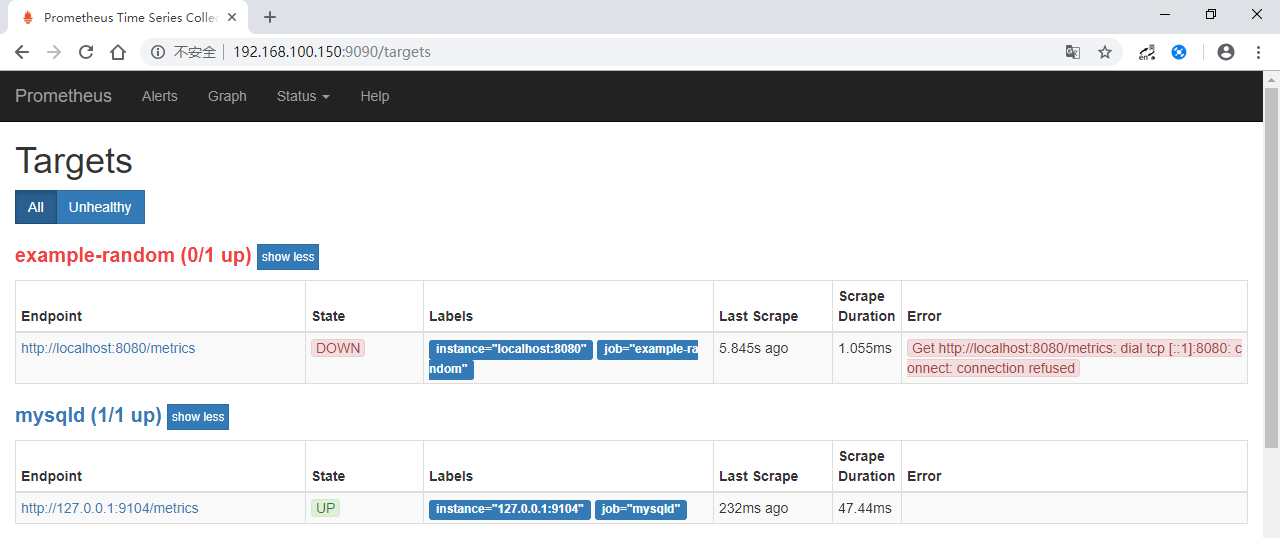
http://192.168.100.150:9090/targets ,显示了已在线的metrics。
http://192.168.100.150:9093/#/alerts
prometheus的metrics
http://192.168.100.150:9090/metrics
mysql的metrics
http://192.168.100.150:9104/metrics
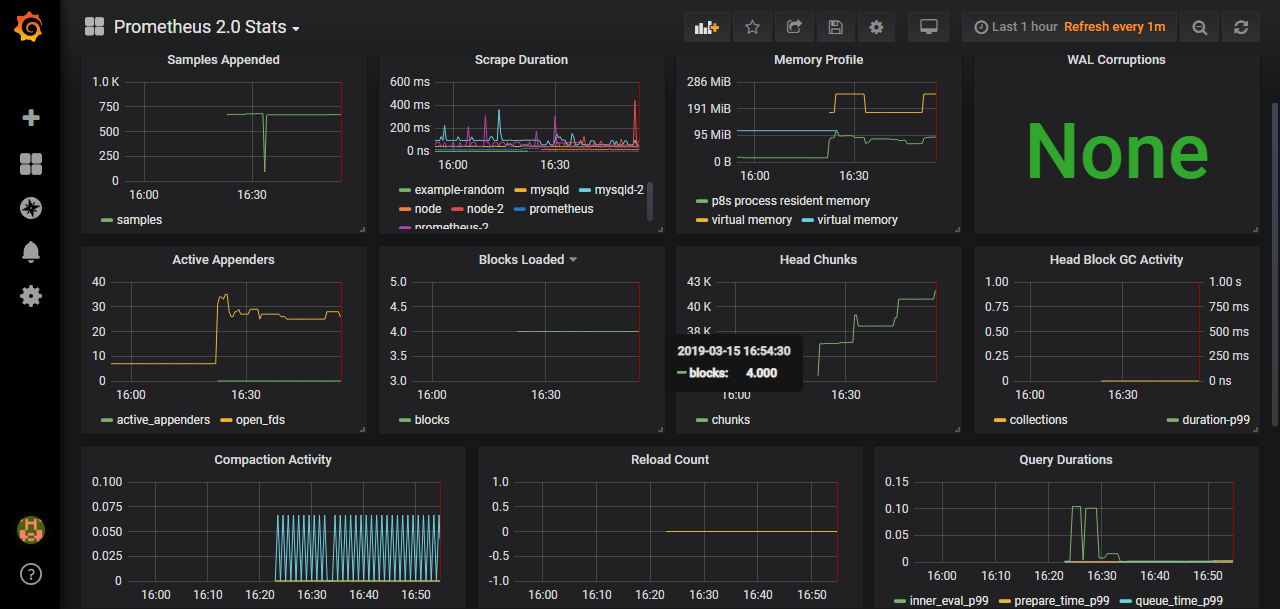
功能测试 在Grafana中,导入Prometheus 2.0 Status仪表板,显示如下:
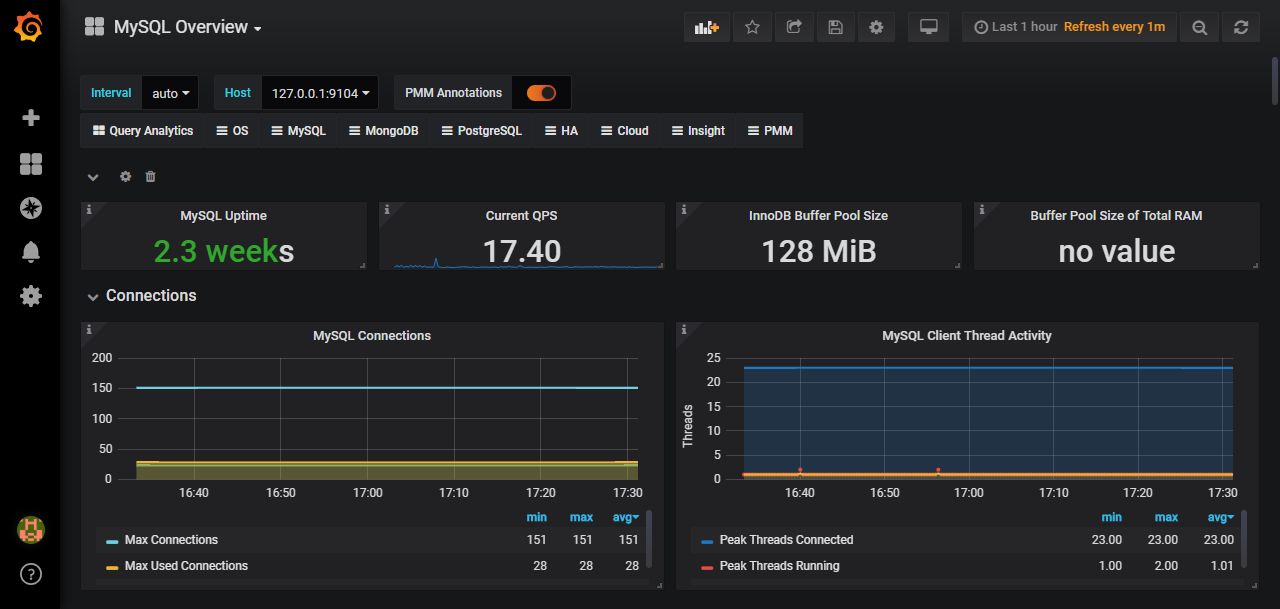
导入Mysql-Overview模板的显示效果:
报警测试:
1 2 3 4 5 6 7 8 go get github.com/prometheus/alertmanager/examples/webhook webhook cat /dev/zero >/dev/null
alertmanager webhook在控制台输出的日志:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 [root@VM_0_2_centos alertmanager]# webhook 2019/03/15 10:49:32 { > "receiver": "web\\ .hook", > "status": "firing", > "alerts": [ > { > "status": "firing", > "labels": { > "alertname": "hostCpuUsageAlert", > "instance": "cvm001", > "monitor": "codelab_monitor", > "severity": "page" > }, > "annotations": { > "description": "cvm001 CPU usage above 20 > "summary": "Instance cvm001 CPU usgae high" > }, > "startsAt": "2019-03-15T02:49:22.839636267Z", > "endsAt": "0001-01-01T00:00:00Z", > "generatorURL": "http://VM_0_2_centos:9090/graph?g0.expr=sum+by > } > ], > "groupLabels": { > "alertname": "hostCpuUsageAlert" > }, > "commonLabels": { > "alertname": "hostCpuUsageAlert", > "instance": "cvm001", > "monitor": "codelab_monitor", > "severity": "page" > }, > "commonAnnotations": { > "description": "cvm001 CPU usage above 20 > "summary": "Instance cvm001 CPU usgae high" > }, > "externalURL": "http://VM_0_2_centos:9093", > "version": "4", > "groupKey": "{}:{alertname=\" hostCpuUsageAlert\" }" >} 2019/03/15 10:52:52 { > "receiver": "web\\ .hook", > "status": "resolved", > "alerts": [ > { > "status": "resolved", > "labels": { > "alertname": "hostCpuUsageAlert", > "instance": "cvm001", > "monitor": "codelab_monitor", > "severity": "page" > }, > "annotations": { > "description": "cvm001 CPU usage above 20 > "summary": "Instance cvm001 CPU usgae high" > }, > "startsAt": "2019-03-15T02:49:22.839636267Z", > "endsAt": "2019-03-15T02:52:52.839636267Z", > "generatorURL": "http://VM_0_2_centos:9090/graph?g0.expr=sum+by > } > ], > "groupLabels": { > "alertname": "hostCpuUsageAlert" > }, > "commonLabels": { > "alertname": "hostCpuUsageAlert", > "instance": "cvm001", > "monitor": "codelab_monitor", > "severity": "page" > }, > "commonAnnotations": { > "description": "cvm001 CPU usage above 20 > "summary": "Instance cvm001 CPU usgae high" > }, > "externalURL": "http://VM_0_2_centos:9093", > "version": "4", > "groupKey": "{}:{alertname=\" hostCpuUsageAlert\" }" >}
当CPU使用率高于20%时,Prometheus Alerts页面的报警状态先后变化顺序:in active -> pending -> firing;恢复后,日志显示resolved。
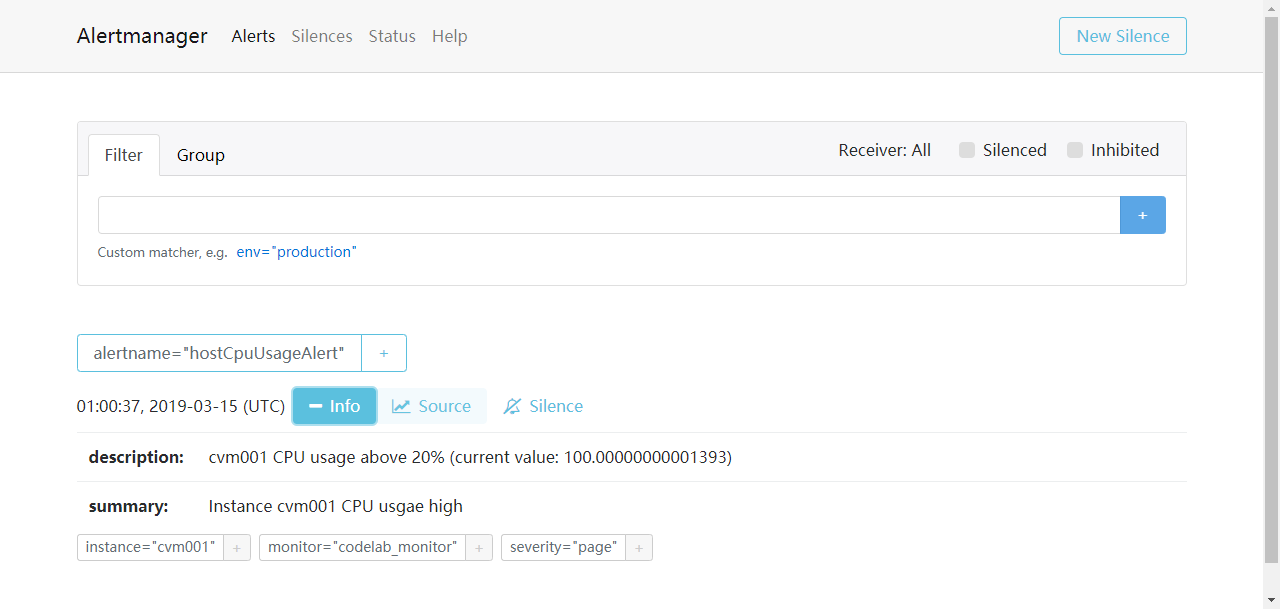
在报警项resolved之前,Alertmanager页面:
通过测试可以看出,webhook方式发出通知是正常的。未测试email和企业微信。
(End)